
こんにちは!今回は、GPT-3をfine-tuningしてキャラクター設定したAIと会話できるアプリをBubbleで構築していきます!
fine-tuningとはモデルを再学習させる手法で、本記事では「つくよみちゃん」というキャラクターの会話データセットを使ってGPT-3 DavinciベースモデルをBubbleでfine-tuningします。さらにfine-tuningしたモデルでチャットアプリを実装する手順とアプリでのやり取りの様子もご紹介しているので、ぜひ最後までお読みください!
なお、チャットアプリは「AIと対話できるチャットアプリをBubbleとGPT-3.5で構築する」の手順通りに既に構築されていることを前提に進めますので、未構築の方はまず上記の記事を参考にチャットアプリの構築を完了させてください。皆さんもぜひご一緒に挑戦してみてくださいね!
■この記事はこんな方におすすめ
- GPT-3/3基本モデルに物足りなさを感じている方
- ノーコードでfine-tuningする方法を知りたい方
- GPTで構築したチャットアプリをもっと磨きたい方
2023/04/20追記
本記事でGPT-3.5と表示していた部分に関しまして、fine-tuningで使用するモデルはDavinchのベースモデル(厳密にはGPT-3)に対して教育をしているため、一部の表記を修正しました。
fine-tuningとは
学習済みのモデルを別のデータセットを使って再学習させる機械学習の手法です。
例えばGPT-3Davinciモデルを、特定のキャラクター設定の下作成した「prompt」と「completion」の組み合わせのデータセットでfine-tuningすると、そのfine-tuningモデルのcompletionリクエストに対して学習データをもとに応答を返してくれるようになります。
ちなみに、GPT-3のキャラクター設定の手法としては、promptの冒頭でキャラクターの設定を入力するという手軽な方法もあります。しかしこの手法では、文字数を割いて詳細にキャラクター設定するほど後に送信できるpromptのトークン数が減るため、長くやり取りを続けられないというデメリットがあります。一方fine-tuningでは、一度のpromptで送信できるトークン数を減らすことなくキャラクター設定が可能です。
APIなどを介して誰もがAIを手軽に利用できるようになった今、fine-tuningでカスタマイズされたモデルに価値が生まれると考えられます。今回の記事でfine-tuningをマスターして、一歩進んだAIチャットアプリを開発しましょう!
今回の目標
- BubbleでGPT-3 Davinciモデルを「つくよみちゃん会話AI育成計画」データセットを使用してfine-tuningする
- fine-tuningモデルで会話アプリを構築する
fine-tuningには「つくよみちゃん会話AI育成計画」で無料公開されているデータセットを使用します。以下のページから利用規約等をご確認のうえダウンロードしてご利用ください。
つくよみちゃん会話AI育成計画(会話テキストデータセットダウンロード)
なお、チャットアプリの構築手順はこちらの記事で構築したアプリをアップデートするかたちで解説しています。まだアプリを構築していない方は上記の記事を元にアプリを構築してください。
また、今回かかる費用について、Bubbleは無料プランで実装しますが、fine-tuningと動作確認に別途費用がかかります(詳細はセクション「fine-tuningの費用」へ)。OpenAI登録時に配布される無料クレジットで利用できる範囲におさまる見込みですが、利用中のOpenAIアカウントがある方は念のため無料クレジットの残額をご確認ください。
「つくよみちゃん」について
今回のチャットアプリの作成には、フリー素材キャラクター「つくよみちゃん」が無料公開している会話テキストデータセット「つくよみちゃん会話AI育成計画」を使用しています。
つくよみちゃん会話AI育成計画とは、フリー素材キャラクター「つくよみちゃん」の公式テキスト素材。会話AIを開発するための機械学習用データで、つくよみちゃんに対する「話しかけ(prompt)」と「お返事(completion)」のセットでできており、2023/3/3時点で469セット用意されています。
■つくよみちゃん会話AI育成計画
© Rei Yumesaki
fine-tuningの費用
fine-tuningの実行とfine-tuningされたモデルの使用には、基本モデルの使用時と異なる費用が掛かります。また、費用はfine-tuningするモデルによって異なります。今回はDavinciモデルをfine-tuningするので、fine-tuningの実行(トレーニング)に$0.0300 /1Kトークン、fine-tuningしたモデルの使用に$0.1200/1kトークンかかります。

ちなみに、今回はfine-tuning用のデータセットをアップロードするAPIと、fine-tuningモデルの情報を取得するAPIも実行しますが、これらには費用はかかりません。あくまで費用はfine-tuningの実行と、fine-tuningモデルの実行について発生します。
※今回の記事作成では、fine-tuningに約$4、fine-tuningしたモデルの動作確認に約$1かかりました。
事前準備
1. fine-tuning用データセットの準備…fine-tuningで使用するトレーニング用データセットはJSONL形式である必要があります。以下を参考にJSONL形式の「つくよみちゃんAI育成計画」をご用意ください。
※fine-tuning
※OpenAIのコマンドラインデータセット準備ツール
2. チャットアプリの構築…こちらの記事を参考に、通常モデルを使用したチャットアプリを構築してください。OpenAIアカウント登録なども含まれています。
実装手順
それではBubbleで実装していきます。構築したチャットアプリを編集モードで開きます。実装手順は、fine-tuningとアプリの修正に分けてご紹介していきます。
fine-tuning
まずはfine-tunigを実行していきます。fine-tuningは1回しか行わないという前提で、API Connectorのイニシャライズで実行していきます。
fine-tuning用データセットのアップロード
まずは、fine-tuningで使うデータセットをアップロードします。以下のOpenAI API「Upload file」を使用します。
BubbleでPlugins>API Connectorを開き、APIをAuthentication「None or self-handled」で作成しCallを追加して以下を参考に設定してください。

- Endpoint…
https://api.openai.com/v1/files - Header key…
Authorization、Value…Bearer API_KEY - Body parameter key1…
purpose、 Value…fine-tune - Body parameter key2…
file、Value…データセットファイルをアップロード
APIキーはOpenAI Manage account>API keysから生成・コピーしてください。
Parameter2では、データセットファイルをアップロードします。
設定できたら「Initialize call」を押下してイニシャライズをします。次のような応答が返ってきたら成功です。応答内の「id」の値を次のfine-tuneの実行で使用しますので、コピーして控えておきます。

Fine-tuneの実行
次に、アップロードしたファイルでモデルをfine-tuningしていきます。以下のOpenAI API「Create fine-tune」を使用します。
データセットのアップロードAPI Callの作成時と同様、Callを追加して以下を参考に設定してください。

- Endpoint…
https://api.openai.com/v1/fine-tunes - Header key…
Authorization、Value…Bearer API_KEY - Content-Type…
application/json - Body…以下の通り
{
"training_file": "<fileid>",
"model": "davinci",
"suffix": "<suffix>"
}
Body parameter key1…
fileid、Value…データセットファイルのid(Upload fileでアップロードしたファイルのidを入力します。※例:file-.......)Body parameter key2…
suffix、Value…test-v6(お好みで設定してください。fine-tuningモデルの名前に使用されます。※例:davinci:ft-personal:SUFFIX-2023-xx-xx-xx-xx-xx)
設定できたらInitialize callを押下してイニシャライズします。次のような応答が返ってきたらfine-tuningを開始できています。

モデルとデータセットのサイズによっては、モデルのトレーニングに数分~数時間かかることがあります(OpenAI)。本記事の検証では約3時間かかりました。Create fine-tune開始後はBubbleのエディタを閉じてもAPIの実行に影響はありません。fine-tuningが完了したらPlaygroundのModel候補にfine-tuningモデルが含まれるようになりますので、それまで待ちましょう。

上記の画像のように、PlaygroundのModel>Fine-tunesに先ほどfine-tuningしたモデルが表示されています。モデル名にはsuffixで設定した「test-v6」が使われています。
なお、「Retrive fine-tuning」APIでfine-tuningの進捗を確認することもできます。こちらのAPIでは、fine-tuningにかかった費用も確認できます。今回は$3.87かかりました。

アプリの修正
fine-tuningが完了したので、チャットアプリを修正していきます。
こちらの記事の通り構築したチャットアプリの、基本モデルで実装した部分をfine-tuningモデルに置き換えて必要な設定を行っていきます。
Send message APIの修正
まずはAPI Connectorで作成したAPI call「Send message」を基本モデルではなくfine-tuningモデルで実行できるように修正します。以下を参考にAPIの設定を確認してください。
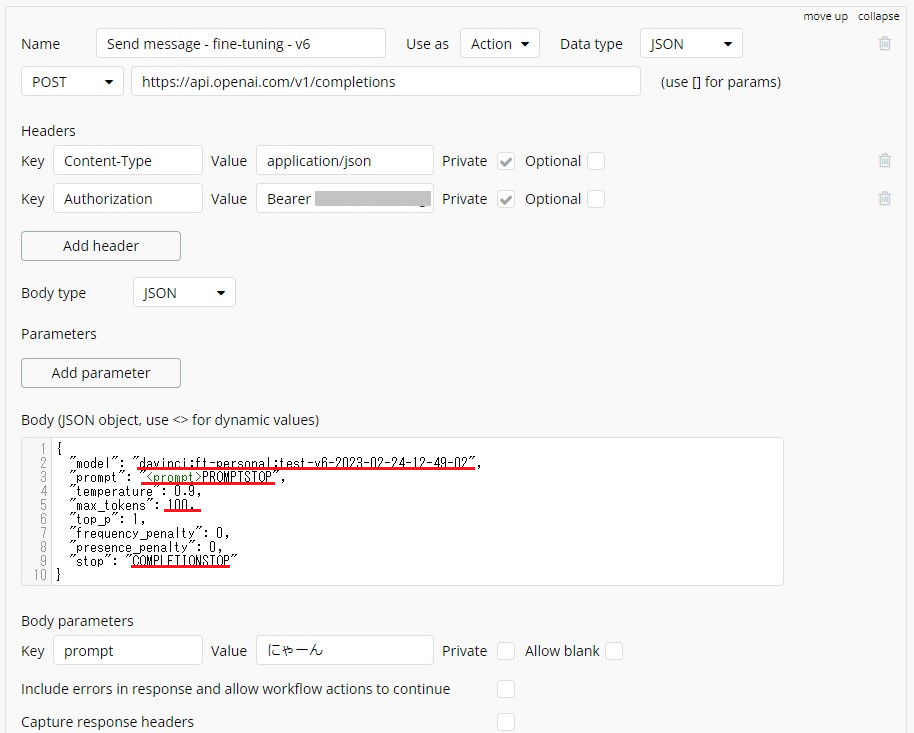
【変更箇所】
- body
model…davinci:ft-personal:test-v6-2023-02-24-12-49-02(使用するfine-tuningモデルの名前に変更します。PlaygroundのModelに表示された名前です。) - body
prompt…<prompt>PROMPTSTOP(promptの停止シーケンスPROMPTSTOPを末尾に追加。) - body
max_tokens…100(今回は長い応答を想定していないため。) - body
stop…COMPLETIONSTOP(completionの停止シーケンス。) - body Parameter
promptのValue…にゃーん(つくよみちゃん育成計画にあった「にゃーん」をイニシャライズ用に設定しました。)
※停止シーケンスについて…OpenAIによると、データセットのpromptとcompletionはそれぞれ異なる固定の停止シーケンスで終了し、実装時にはデータセットと同じ停止シーケンスを用いてpromptをフォーマット化する必要があります。本記事の検証では、停止シーケンスとしてpromptにはPROMPTSTOP、completionにはCOMPLETIONSTOPを使用したので、それを反映した設定内容になっています。
それでは、fine-tuningのデータセットにあったメッセージを送信するとどのような応答が得られるかイニシャライズで確認してみましょう。Initialize callを押下して以下のような応答が返ってきたら成功です。

今回、応答内容はデータセットと同じ回答になりました。
Workflowの修正
Send message APIを新規で作成した場合はWorkflowを修正します。通常モデルで作成していたAPIを修正した場合はWorkflowの修正はありませんので、動作確認に進んでください。
チャットページの送信アイコンを押下して実行する一連のWorklfowのStep8を、Plugins>「GPT-3.5 - Send message - fine-tuning - v6」(前のセクションで作成したSend message API)に変更します。
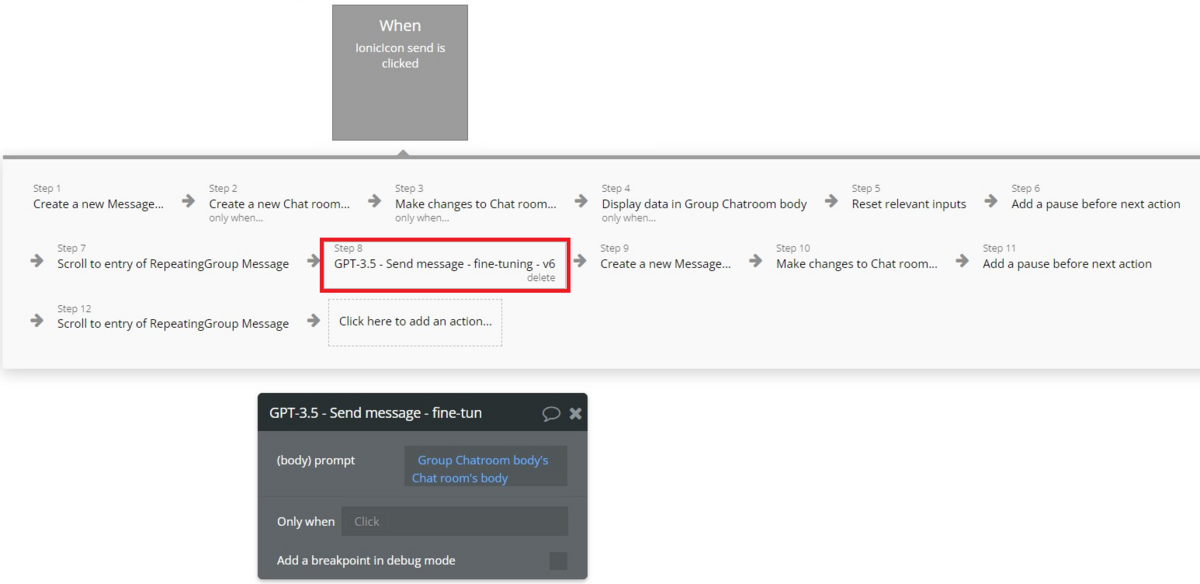
上記以外の部分で変更箇所はありません。
動作確認
それでは、実際にメッセージを送信してアプリを動かしてみましょう!修正したチャットページをPreviewで開き、まずはデータセットの話しかけに含まれるメッセージを送信してみます。
以下はデータセットと同じ応答が返ってきた例です。



以下は、データセットの内容とは異なるものの単語の選択や言い回しがつくよみちゃんっぽいcompletionを返した例です。



一方で、つくよみちゃんのキャラクターと矛盾したcompletionもありました。

ここまではやり取りが成立していると言えるケースですが、こちらはやや意味不明でやり取りが成立していない例です。


特に一つのチャットルームでやり取りを続けると、会話の方向は間違っていないがなんとなく話が噛み合わない展開になることが多くありました。

本記事の検証に当たって確認できた範囲では、データセットに含まれる話しかけをpromotで送信した場合では、データセットのお返事と同じ応答が返されることが最も多いという結果になりました。データセットに含まれるからと言って必ずその通りの応答が返されるわけではないようです。
続いて、データセットの話しかけに含まれないメッセージを送信してみます。
以下は、つくよみちゃんらしい応答が返ってきた例です。
※つくよみちゃん会話AI育成計画から想像できる範囲の応答を「つくよみちゃんらしい」としています。



一方で、以下はつくよみちゃんらしくない応答が返ってきた例です。

受け取り方によっては冷たい応答ですね。

温かみを感じられるニュアンスはつくよみちゃんらしいですが、意味の通らない文章になっていますね。
しかし、全体で見ると、「…」や「!」の使い方も含めた言い回しがつくよみちゃんらしい応答が返されることが多いという結果になりました。
上記の結果を踏まえると、「つくよみちゃんAI育成計画」でfine-tuningしたモデルで構築するチャットアプリは、過去のやり取りを踏まえた連続性のある会話ができるアプリではなく、簡単な話しかけから始まる一往復のやり取りを繰り返すアプリが望ましいと言えそうです。
ちなみに、例の数が2倍になるたびにパフォーマンスが直線的に向上する傾向がある(OpenAI)と言われているので、複雑な会話を成立させたい場合はデータセット量を増やしてfine-tuningを試してみてくださいね。
まとめ
今回はGPT-3をBubbleでfine-tuningする方法と、fine-tuningモデルでチャットアプリを実装する方法をご紹介しました。fine-tuningモデルで実装するときのポイントは、メッセージ送信時のpromptに停止シーケンスを含むということでした。
今回は、厳密なキャラクター設定と文脈が保たれたやり取りの実現まではたどり着けませんでしたが、つくよみちゃんとの簡単なやり取りを楽しむことができましたね。fine-tuningモデルをうまく活用して、アプリの新たな価値付けに挑戦してみてください!