
こんにちは!
今回の記事では、Bubbleでの正規表現の書き方と正規表現を用いた機能の実装例をレベルごとにご紹介します。
正規表現はプログラミングだけでなくテキストエディタでも用いられることがありますが、Bubbleで正規表現を設定しようとすると手こずることがあります。そんなときに手元に置いて実装を進めていただきたい記事となっています。
正規表現の基礎となるメタ文字から、具体的な事例までレベルごとにご紹介しておりますので、正規表現に困ったときはぜひご参考にしてみてください!
正規表現とは
文字列のパターンを表記する表現方法の一つ。プログラミング言語やテキストエディタによって異なります。BubbleではJavaScriptの正規表現を採用しています。
Bubbleで正規表現を使うには
Bubbleで正規表現を使えるのは、Text type入力時の演算子「:extract with regex」と「:find & replace」です。また、「:filterd」>「Advanced」の選択で「:extract with regex」を用いてフィルターの設定をすることもできます(「:filtered」のRegexについては「レベル2:データ検索機能実装時に使える正規表現」の段落で解説します)。
:extract with regex
「パターンにマッチする部分を抽出する」演算子です。
入力された文字列から一部だけを抽出したいときに使用します。抜き出したいパターンを正規表現で指定します。

:find & replace
「パターンにマッチする部分を見つけて置き換える」演算子です。
あるパターンを指定の単語や文字列で置き換えたいときに使用します。「Use a regex pattern」のチェックをオンにすることで、被置き換え対象のパターンを正規表現で指定できるようになります。

なお、「Use a regex pattern」のチェックをオフにして、正規表現を使わず発見と置き換えを実行することもできます。
正規表現レベル1:基本と頻出正規表現
Bubbleでの正規表現の表記方法をご紹介します。
メタ文字
まずは、正規表現の基本となる「メタ文字」をご紹介します。メタ文字とは、プログラムにとって特別な意味を持つ文字のことです。以下のメタ文字を用いて正規表現を作ります。
| メタ文字 | 意味 |
|---|---|
. |
あらゆる一文字 |
\w |
英数字一文字 |
\d |
数字一文字 |
^ |
行の先頭 |
$ |
行の終わり |
[ ] |
カッコ内で指定した文字のいずれか |
[^] |
^の後ろの文字以外の文字 |
* |
直前の文字がない、または、直前の文字が一個以上連続する |
+ |
直前の文字が最低一個以上ある |
? |
直前の文字が全くないか一つだけある |
| |
区切られた文字列のいずれかの文字列が存在する |
() |
カッコ内の文字列をグループ化する |
\ |
直前のメタ文字をメタ文字として扱わない(通常の文字として扱う) |
\n |
改行文字 |
\s |
空白文字(スペース・タブ文字・改行・改ページ) |
\S |
非空白文字 |
頻出表現
よく使われる正規表現をご紹介します。以下はBubbleで正常に認識できる表記法なので、コピーしてそのまま使って問題ありません。
| パターン | 正規表現 |
|---|---|
| 全角文字 | [^\x01-\x7E] |
| 半角英数字 | [\x00-\x7F] |
| 半角英数字(記号除く) | \w |
| 半角数字 | \d |
| 数字以外の半角文字 | \D |
| ひらがな | [\u3040-\u309F] |
| カタカナ | [\u30A0-\u30FF] |
| 漢字 | [々〇〻\u3400-\u9FFF\uF900-\uFAFF]|[\uD840-\uD87F][\uDC00-\uDFFF] |
| 郵便番号 | ^\d{3}-\d{4}$ |
| URL(英字のみ) | ^https?:\/\/[-_.!~*\'()a-zA-Z0-9;\/?:\@&=+\$,%#]+$ |
| 固定電話番号 | ・ハイフンあり…^0\d(-\d{4}|\d-\d{3}|\d\d-\d\d|\d{3}-\d)-\d{4}$・ハイフンなし…^0\d(\d{4}|\d\d{3}|\d\d\d\d|\d{3}\d)\d{4}$ |
| 携帯電話番号 | ・ハイフンあり…^0[789]0-\d{4}-\d{4}$・ハイフンなし…^0[789]0\d{4}\d{4}$ |
| Emailアドレス | ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ |
| パスワード(大文字アルファベット・記号を少なくとも一つ含む8~24文字) | ^(?=.*[A-Z])(?=.*[.?/-])[a-zA-Z0-9.?/-]{8,24}$ |
※上記の表記方法は一例です。
電話番号
Bubbleでは、Input ElementのContent formatを「US phone」に設定することで、アメリカの電話番号の表記法と合致しているかチェックすることができます。ただし、アメリカ以外の固定電話や携帯電話番号の表記チェックはできないため、Content formatは「Text(numberes only)」にして、電話番号の正規表現を使って正しい表記になっているかを確認するのがおすすめです。
Emailアドレス
電話番号と同じく、Input ElementのContent formatを「Email」に設定することでEmailアドレスの表記法と合致しているかをチェックすることができます。そのためメールアドレス登録時の表記チェックとしての出番はほぼありませんが、自由入力した文中からメールアドレスを抽出したい場合などに便利です。
パスワード
Bubbleでは、ユーザー情報としてのパスワード登録時にSettings>Generalタブで「Define a password policy」をオンにすることで、パスワードの最短文字数・数字の要不要・大文字要不要・非アルファベット文字数を設定することができますね。そのため、基本的にはパスワードポリシーの適用で十分と考えられますが、パスワードをより厳密に設定したい場合は正規表現を用いてチェックするのがおすすめです。
レベル2:データ検索機能実装時に使える正規表現
続いて、BubbleでDo a search forなどを使ってデータ検索機能を実装するときに便利な正規表現をご紹介します。
Bubbleで正規表現に困ると言えば検索機能実装シーンがほとんどだと思いますので、ぜひここで検索用途に合わせた正規表現をチェックしておきましょう!
実際に検索機能を実装しながら正規表現の設定方法をご紹介していきます。
実装準備
検索対象のデータとして、Regex testというData typeを作成し、Body fieldにテスト用の文章を登録したデータを3件作成しました。
検索ページには、検索ワードを入力するInput Elementと検索を実行するButon Elementを配置します。検索結果の表示用にRepeating Groupも配置し、セル内に表示内容を「Current cell’s Regex Test's body」としたText elementを配置します。

単一キーワードを含む/含まない検索
まずは、入力された単一キーワードを含む/含まない検索を実装します。使用する正規表現は以下の通りです。
・「~を含む」検索の正規表現
| 検索方式 | 正規表現 |
|---|---|
| 部分一致(特定の文字・文字列を含む) | .*DYNAMIC-DATA:trimmed |
| 前方一致(特定の文字・文字列で始まる) | ^DYNAMIC-DATA:trimmed |
| 後方一致(特定の文字・文字列で終わる) | DYNAMIC-DATA:trimmed$ |
最初の例として、入力したワードを含むデータを検索する部分一致検索機能を実装していきます。
Button Elementを押下してWorkflowを作成します。
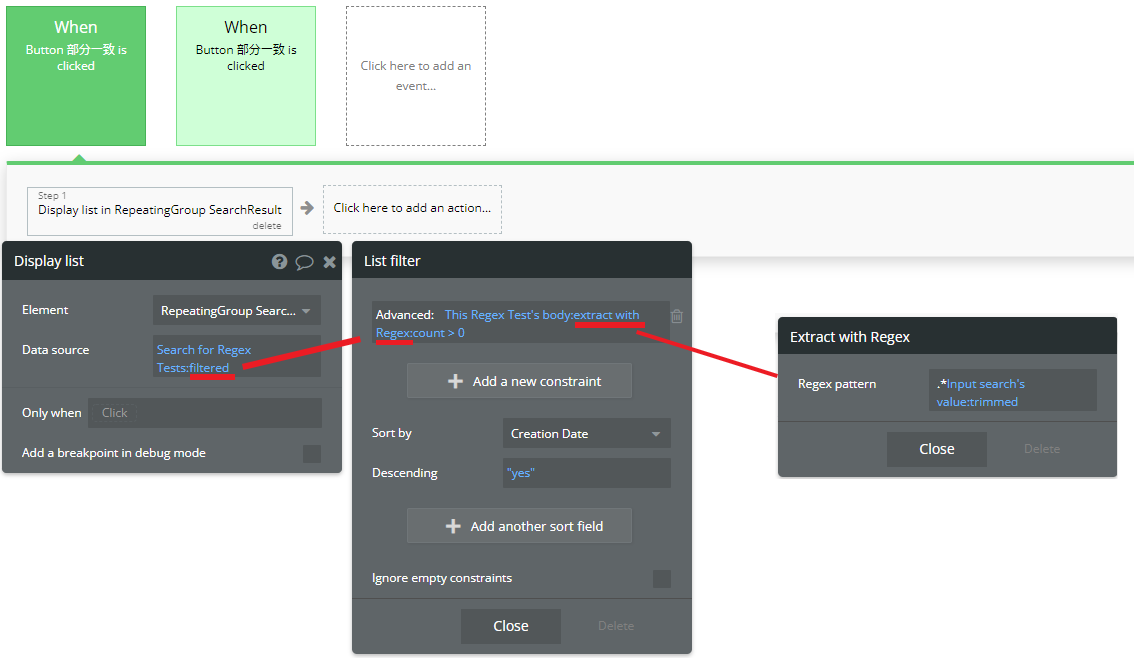
Step1に「Display list」を設定し、Elementに検索結果の表示用で配置したRGを選択します。Data sourceは「Do a search for…」でTypeを「Regex Test」にします。このときConstraitを追加しての設定は不要です。
Display listのActionに戻り、Data Sourceの「More」を押下して「:filtered」を選択します。「List filter」の設定で「Add a new constrait」を押下して、まずは「Advanced...」を選択します。Advancedの中身は「This Regex Test's body:extract with Regex:count > 0」とします。「Extract with Regex」のRegex patternは、正規表現を用いて「.*Input search's value:trimmed」に設定します。
前方一致・後方一致で検索機能を実装したいときも設定方法は同じです。「List filter」>「Advanced...」>「Extract with Regex」のRegex patternの設定だけが異なりますので、以下を参考に設定してください。
※前方一致

※後方一致

また、「~を含まない」検索機能を実装したいときも実装方法は同じです。「~を含む」検索Workflowの「List filter」>「Advanced...」>「Extract with Regex」のRegex patternを以下の正規表現を用いて設定してください。
・「~を含まない」検索の正規表現
| 検索方式 | 正規表現 |
|---|---|
| 部分不一致(特定の文字・文字列を含まない) | ^(?!.*DYNAMIC-DATA:trimmed).*$ |
| 前方不一致(特定の文字・文字列で始まらない) | ^(?!DYNAMIC-DATA:trimmed).+$ |
| 後方不一致(特定の文字・文字列で終わらない) | ^.*(?<!DYNAMIC-DATA:trimmed)$ |
なお、「~を含まない」検索は、「~を含む」正規表現を使って実装することもできます。「~を含むパターンがゼロである」という意味で「List filter」を設定する方法です。具体的には、「List filter」>「Advanced...」>「Extract with Regex」の設定で「~を含む」検索の正規表現を設定し、「Advanced...」は「This Regex Test's body:extract with Regex:count is 0」とします。
※例:「部分不一致」の検索を部分一致の正規表現を用いて設定

複数キーワード(AND/OR)検索
一つの検索ワードInputに複数のワードが入力された場合、特に設定をしていないとBubbleでは日本語データのAND/OR検索をすることができませんが、正規表現を用いて検索の設定をすることでその問題を回避できます。
・AND/OR検索の正規表現
| 検索方式 | 正規表現 |
|---|---|
| AND検索(入力されたワードをすべて含む) | ^(?=.*STRING1)(?=.*STRING2).*$ |
| OR検索(入力されたワードのいずれかを含む) | .*(STRING1|STRING2) |
実装していきます。まずは検索ワードを保存するData typeを作成します。今回は、「Regex result」というtype名で、検索ワードを保存するfield(field名:word、type: text)を持つData Typeを作成しました。
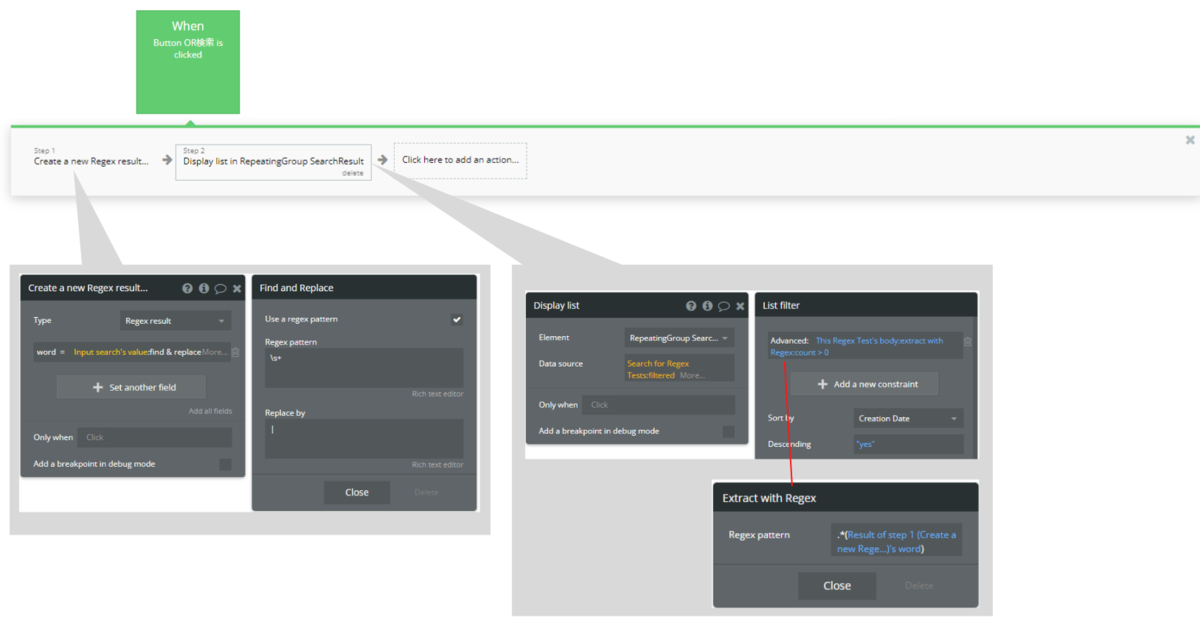
・Workflow Step1
Workflowを作成します。「検索」のButtonを押下してWorkflowを作成し、Step1に「Data(things)」>「Create a new thing」を設定します。保存する値は、Inputに入力されたワードを区切っているスペースを、AND検索で使用する正規表現の文字列どうしをつなぐ部分に置き換えた値にしたいので、「Input search’s value:find&replace」とします。「find & replace」の設定で「Use a regex pattern」のチェックをオンにしたら、「Regex pattern」には「空白文字」を意味する「\s+」を、「Replace by」には「)(?=.*」を設定します。これで、スペース区切りで入力されたワードに、ワード数に関わらず正規表現を適用する準備ができました。

・Workflow Step2
Step2には、「Element Actions」>「Display list」を設定し、Elementには結果表示用に配置したRGを選択します。Data sourceは「Do a search for…」でTypeを「Regex Test」にします。このときConstraitを追加しての設定は不要です。Display listのActionに戻り、Data Sourceの「More」を押下して「:filtered」を選択します。

「List filter」の設定で「Add a new constrait」を押下して、まずは「Advanced...」を選択します。Advancedの中身は「This Regex Test's body:extract with Regex:count > 0」とします。「Extract with Regex」のRegex patternは、正規表現を用いて「^(?=.*Result of step1’s word).*$」に設定します。これで、入力されたキーワードの前後に欠けていた前後の正規表現が追加され、正しく設定することができました!この方法であれば、入力されたキーワードが何語でも対応できます。


ではDebuggerをstep by stepで見ながらどのようにWorkflowが進むか見てみましょう。
Inputに「今日 テスト」と入力して「検索」ボタンを押下します。まずStep1で、各キーワードの間のスペースを正規表現のつなぎの部分に置き換えました。

Step2で、Step1の結果の前後の欠けている正規表現が補われました。

結果、「今日」と「テスト」両方を含むデータのみが表示されます。

また、OR検索もAND検索と同じ手順で実装できます。AND検索のWorkflowのStep1の「find & replace」で「Regex pattern」には「空白文字」を意味する「\s+」を、「Replace by」には「|」を設定します。Step2の「List filter」>「Extract with Regex」のRegex patternは「.*(Result of step1’s word)」と設定します。
これで、入力されたキーワードのいずれかを含むOR検索も実装できました。
レベル3:様々な実装例
この段落では、正規表現を用いる具体的なケースをご紹介します。
指定の記号を先頭とするパターンを抽出する
今回は、ユーザーが自由に入力した文章からハッシュタグで始まるパターンを抽出する機能を実装します。
| 正規表現 | 意味 |
|---|---|
#\S+ |
#で始まる非空白文字一文字以上の連続のパターン |
文章を入力するmultiline input elementとButton Elementを配置します。
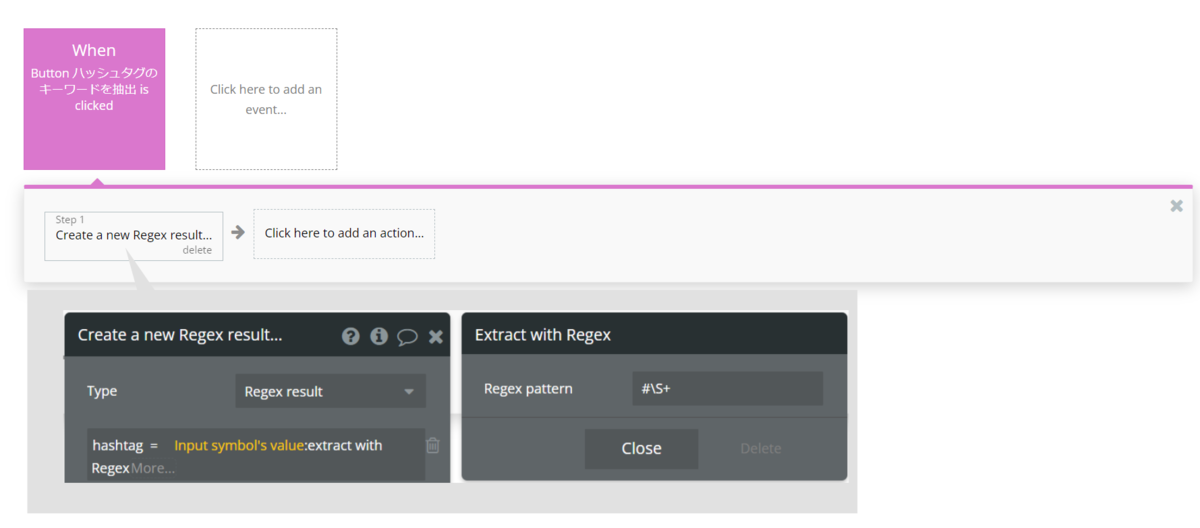
Button Elementを押下してWorkflowを作成します。Step1に「Data(Thing)」>「Create a new thing...」で、Multiline Inputに入力された文章をText typeのフィールドに保存します。保存する値を「Input symbol's value:extract with regex」とし、extract with regexのRegex patternに「#\S+」を設定します。
Workflowはこれで完成です。
テスト用の文章を入力して動作確認をしてみます。
以下のように、ハッシュタグと改行を含む文章を入力してみます。
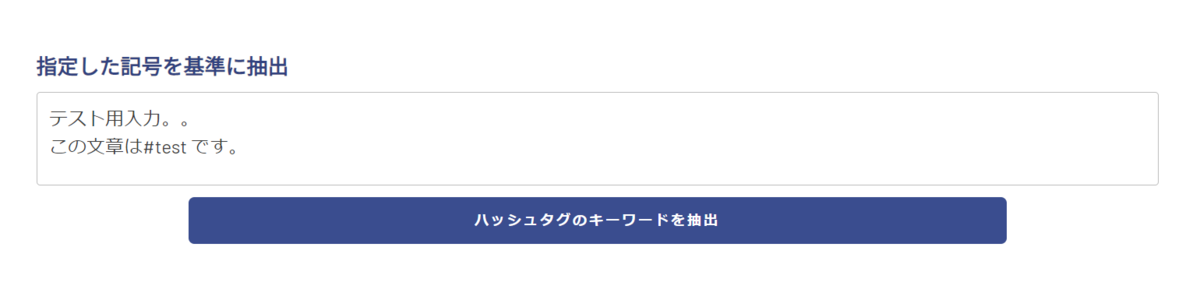
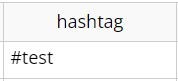
Button押下で「#test」のみを抽出して保存できました。
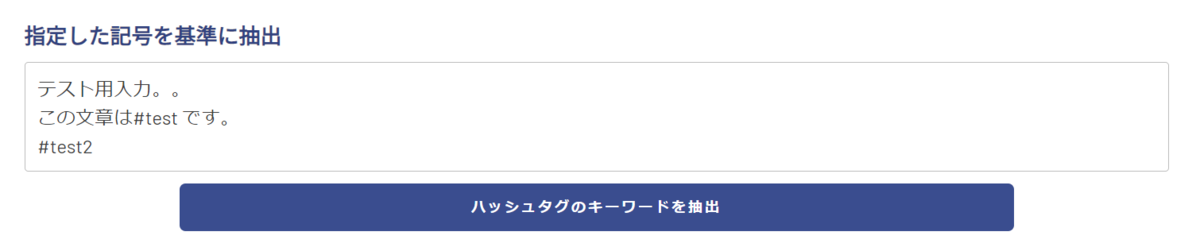
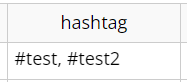
ハッシュタグを2つ含む場合、両方が抽出されます。
連続するパターンを分割して抽出し、不要な文字を削除する
次に、URLから全てのクエリパラメータとその値を抽出する機能を実装します。API Connectorの応答URLからパラメータを抽出したいとき等に有効な方法です。
| 正規表現 | 意味 |
|---|---|
[\?|&]([^&]+) |
?または&で始まり、次の&の前まで続くパターン |
ページにURLを入力するInput elementとButton Elementを配置します。

①パラメータと値の組み合わせを先頭の?または&を含むかたちですべて分割して抽出し、②先頭の?または&を削除するという2つのステップに分けてWorkflowを設定します。
Button押下でWorkflowを作成します。Step1には「Data(Thing)」>「Create a new thing」を設定します。テスト用に作成したData type(今回は、検索機能実装時に作成した「Regex test」)のText fieldを保存先にして、値は「Input symbol’s value:extract with regex」とします。Regex patternは「[\?|&]([^&]+)」を設定します。
※Regex patternを「パラメータ名([^&]+)」とすることで、指定のパラメータとその値を抽出することができます。

Step2には「Data(Thing)」>「Make changes to thing」を設定します。Things to changeを「Result of step1」とし、保存する値は「This regex result’s parameter:find & replace」とします。ここで?または&を削除したいので、Regex patternを「[\?|&]」に、Replace byは空欄に設定します。
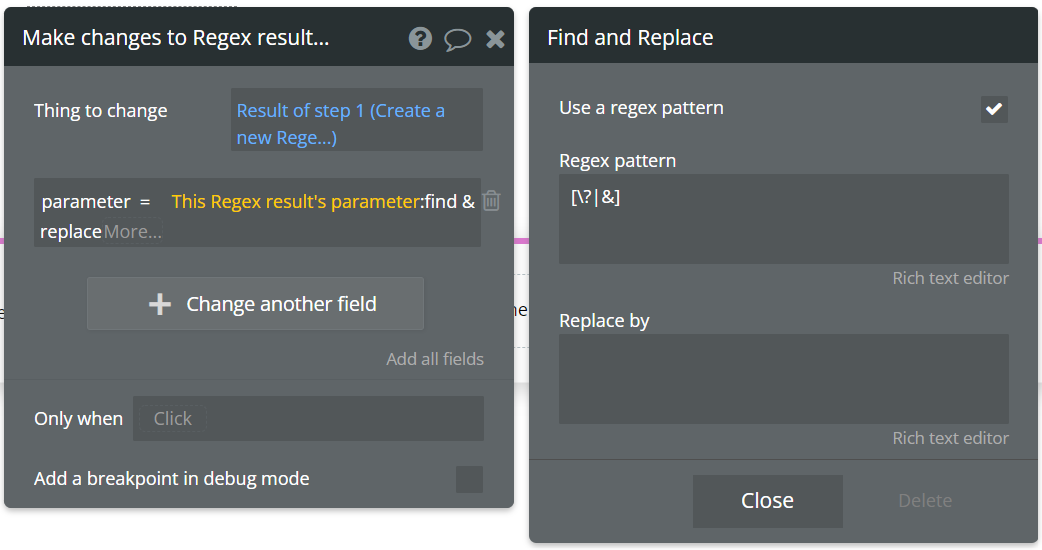

これでWorkflowの設定は完了です。Debuggerを見ながら確認してみましょう。
URLは、BubbleのエディターのURLを入力します。Buttonを押下すると、まずすべてのクエリパラメータと値が抽出されます。
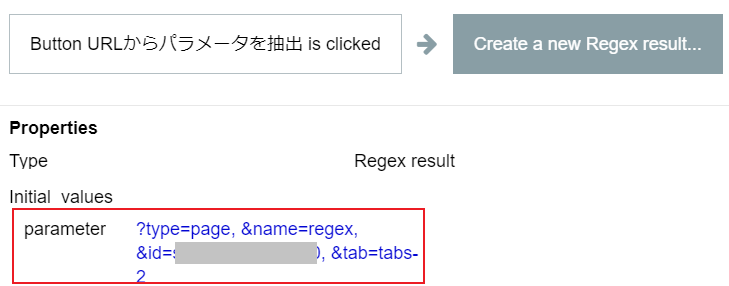
Step2で、それぞれの先頭についている?と&が削除されました。

先頭からX文字目からY文字のパターンを抽出する
続いては、文字数が固定の文字列の先頭からX文字目からY文字のパターンを抽出する機能を実装します。
| 正規表現 | 意味 |
|---|---|
(?<=^.{5}).{4} |
先頭から6文字目から4文字のパターン |
※指定したい文字数に応じて上記の数値を変更して使ってください。
今回は例として「A000-0000-0000」のようなパターンから、中間の「0000」の部分を抽出します。
文字列を入力するInput ElementとButtonを配置します。

Buttonを押下でWorkflowを作成し、Step1に「Data(Thing)」>「Create a new thing」を設定します。Input Elementに入力された文章をText typeのフィールドに保存します。保存する値を「Input symbol's value:extract with regex」とし、extract with regexのRegex patternに「(?<=^.{5}).{4}」を設定します。
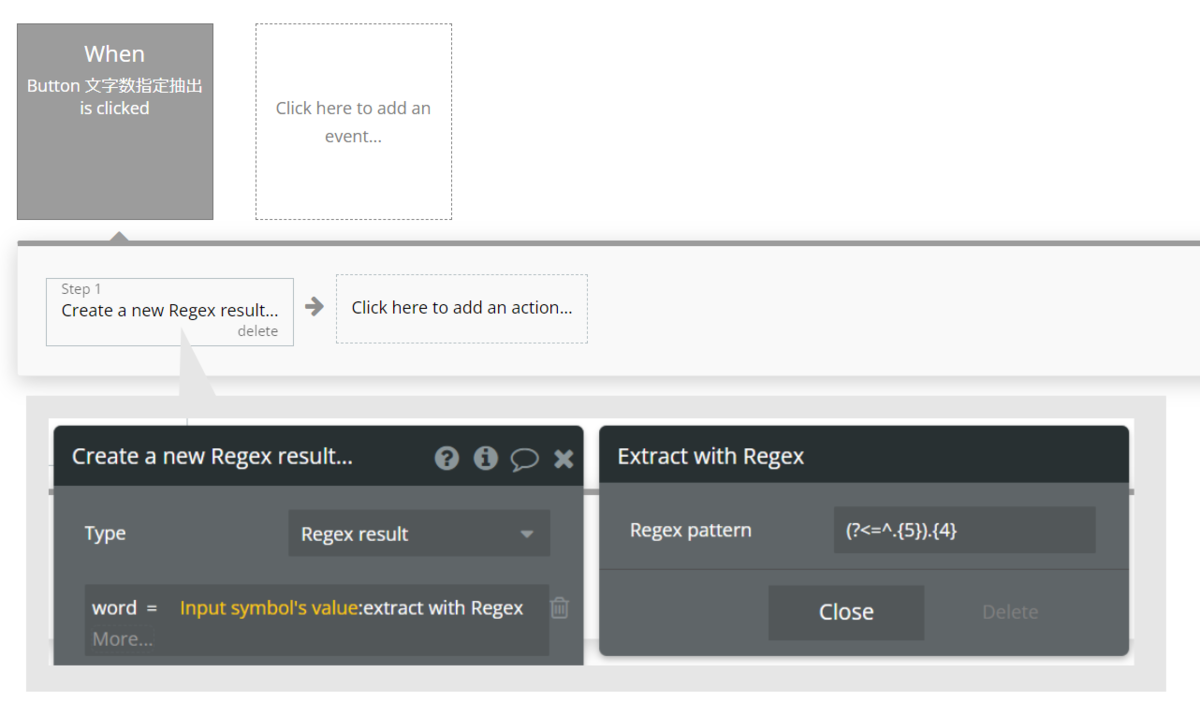
Workflowはこれで完成です。
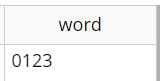
動作確認をしてみます。

先頭から6文字目の数字4桁の部分が保存されていますね!
URLのドメインまでの部分を抽出する
続いては、URLのドメインまでの部分を抽出する機能を実装します。
| 正規表現 | 意味 |
|---|---|
^(?:https?://)?(?:[^@/\n]+@)?(?:www.)?([^:/?\n]+) |
ドメインまでのURL |
ページにはURLを入力するInput ElementとButton Elementを配置します。

Buttonを押下してWorkflowを作成し、Step1に「Data(Thing)」>「Create a new thing....」を設定します。Input Elementに入力された文章をText typeのフィールドに保存します。保存する値を「Input symbol's value:extract with regex」とし、extract with regexのRegex patternに「^(?:https?://)?(?:[^@/\n]+@)?(?:www.)?([^:/?\n]+)」を設定します。
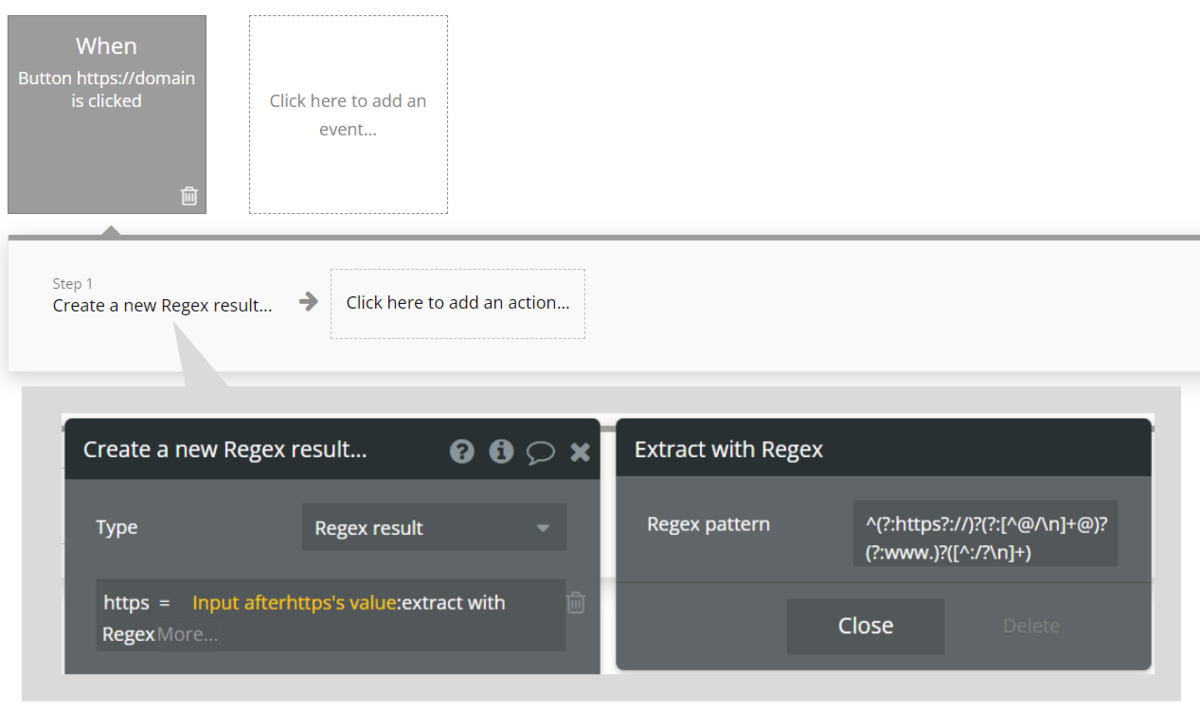
Workflowはこれで完成です。
テスト用のURLを入力して動作確認をしてみます。

「version-test」やページ名の表示などを除いたドメインまでの部分が保存されています。

指定の記号の前後を、記号を含まず抽出する
続いては、@など指定の記号の前後のパターンを記号を含まずに抽出する機能を実装します。メールアドレスの@前のパターンをユーザー名として登録したい場合などに便利な機能です。
| 正規表現 | 意味 |
|---|---|
[^@]([^@]+)$ |
@の後ろのパターン |
^[^@]+[^@] |
@の前のパターン |
※どちらも@を含まない正規表現。
ページには、メールアドレスを入力するInput ElementとButton Elementを2つ配置します。

まず「@より後ろを抽出」するWorkflowを設定します。Step1に「Data(Thing)」>「Create a new thing....」を設定します。Input Elementに入力された文章をText typeのフィールドに保存します。保存する値を「Input symbol's value:extract with regex」とし、extract with regexのRegex patternに「[^@]([^@]+)$」を設定します。
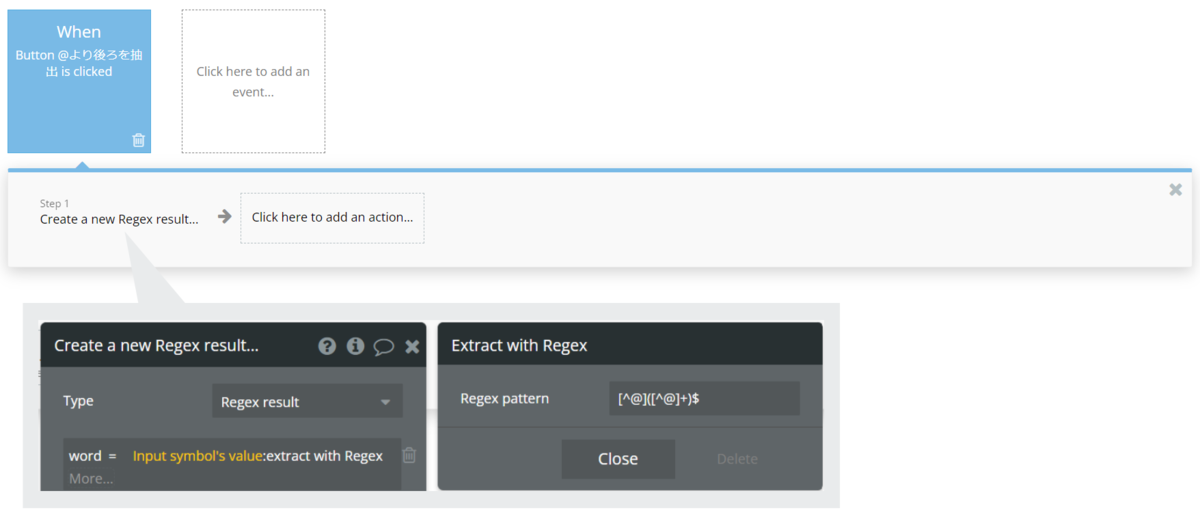
テスト用のメールアドレスを入力して動作確認をしてみます。

@より後ろが保存されています。

次に、「@より前を抽出」するWorkflowを設定します。Step1に「Data(Thing)」>「Create a new thing....」を設定します。Input Elementに入力された文章をText typeのフィールドに保存します。保存する値を「Input symbol's value:extract with regex」とし、extract with regexのRegex patternに「^[^@]+[^@]」を設定します。
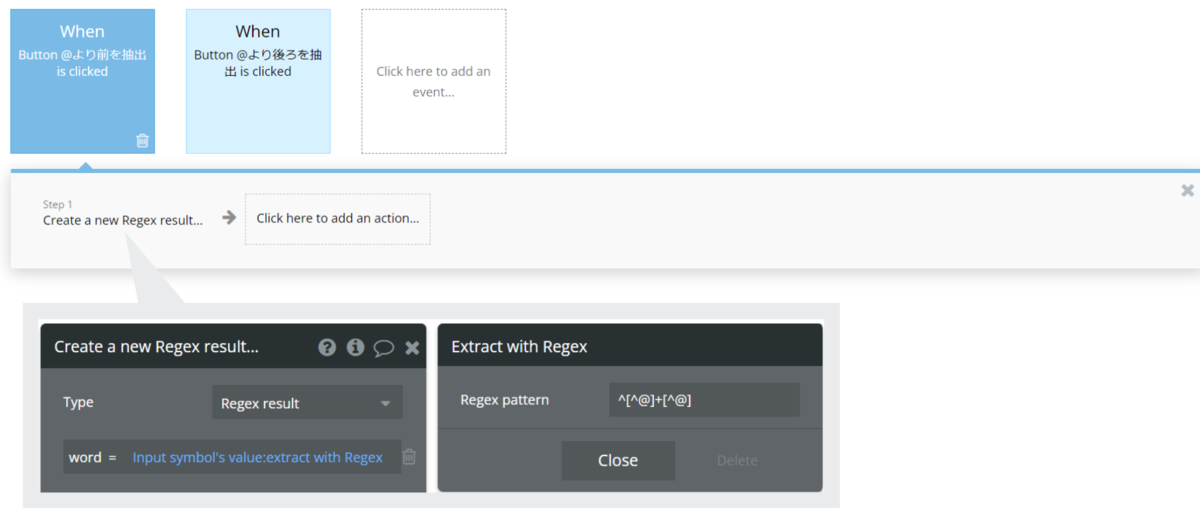
先ほどと同じテスト用メールアドレスを入力して動作確認をしてみると、@より前が保存されていますね。

正規表現チェックツール
正規表現を自分で書く場合は、Bubbleで実装する前に以下のようなチェックツールを使って正しく書けているかを確認するのがおすすめです。
・regular expressions 101(Bubble推奨)
・RegExr
・正規表現チェッカー
まとめ
今回は、Bubbleでの正規表現の書き方と正規表現を用いた機能の実装例をご紹介しました。正規表現は難しいものもありますが、慣れれば色々な機能に応用できます。ぜひご参考にしてくださいね!